Facebook’s user interface for discussions is terrible. Here are some of the top annoyances for me:
- Slow. Quite often I get those blank rectangles which seems to be a React thing when content is pending.
- UI shift. When you go a post it shows the number of comments with some algorithmically selected comments below the post. When you click on “View more answers” or the comments link, the UI changes to show the comments in a new panel.
- Difficult navigation. Everything defaults to the algorithm’s idea of what it calculates you want to see (or what Facebook wants me to see). So we get “Most relevant” and “Top comments.” I always want to see all the comments (spam aside) with the most recent comment threads at the top. So to get to something approaching that view I have to click first, View more answers, and then drop-down “Top comments” to select one of the other options.
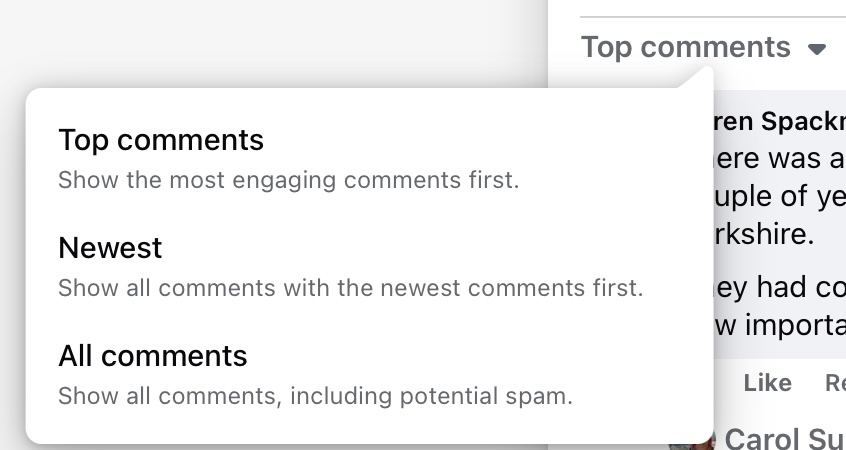
- Even “All comments” does not show all comments, but only the top level without the replies.
Facebook is also a horrible experience for me thanks to the news feed concept, which pushes all manner of things at me which I do not want to see or which waste time. I have learned that the only way I can get a sane experience is to ignore the news feed and click the search icon at top left, then I get a list of groups or pages I have visited showing which have new posts.
Do not use Facebook then? The problem is that if the content one wants to see is only on Facebook it presents a bad choice: use Facebook, or do not see the content.
Reddit by contrast is pretty good. You can navigate directly to a subreddit. Tabs for “hot” and “new” work as advertised and you can go directly to “new” by the logical url for example:
https://www.reddit.com/r/running/new/
Selecting a post shows the post with comments below and includes comment threads (replies to comments) and the threads can be expanded or hidden with +/- links.
The site is not ad-laden and the user experience generally nice in my experience. The way a subreddit is moderated makes a big difference of course.
The above is why, I presume, reddit is the best destination for many topics including running, a current interest of mine.
Why is Facebook so poor in this respect? I do not know whether it is accident or design, but the more I think about it, the more I suspect it is design. Facebook is designed to distract you, to show you ads, and to keep you flitting between topics. These characteristics prevent it from being any use for discussions.
If I view the HTML for a reddit page I also notice that it is more human-readable, and clicking a random topic I see in the Network tab of the Safari debugger that 30.7 KB was transferred in 767ms.
Navigate back to Facebook and I see 6.96 MB transferred in 1.52s.
These figures will of course vary according to the page you are viewing, the size of the comment thread, the quality of your connection, and so on. Reddit though is much quicker and more responsive for me.
Of course I am on “Old reddit.” New reddit, the revamped user interface (since 2017!) that you get by default if not logged in with an account that has opted for old reddit, is bigger and slower and with no discernible advantages. Even new reddit though is smaller and faster than Facebook.
Tip: If you are on new reddit you can get the superior old version from https://old.reddit.com/











